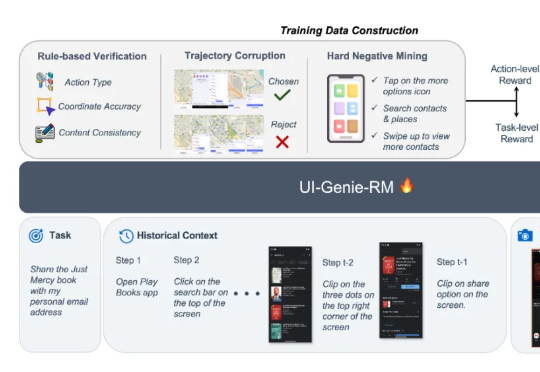
vivo AI Lab提出自我进化的移动GUI智能体,UI-Genie无需人工标注实现性能持续提升
vivo AI Lab提出自我进化的移动GUI智能体,UI-Genie无需人工标注实现性能持续提升本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
来自主题: AI技术研报
8246 点击 2025-11-08 11:00
 搜索
搜索
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
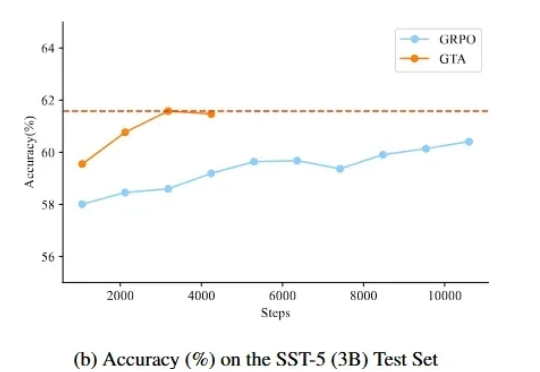
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
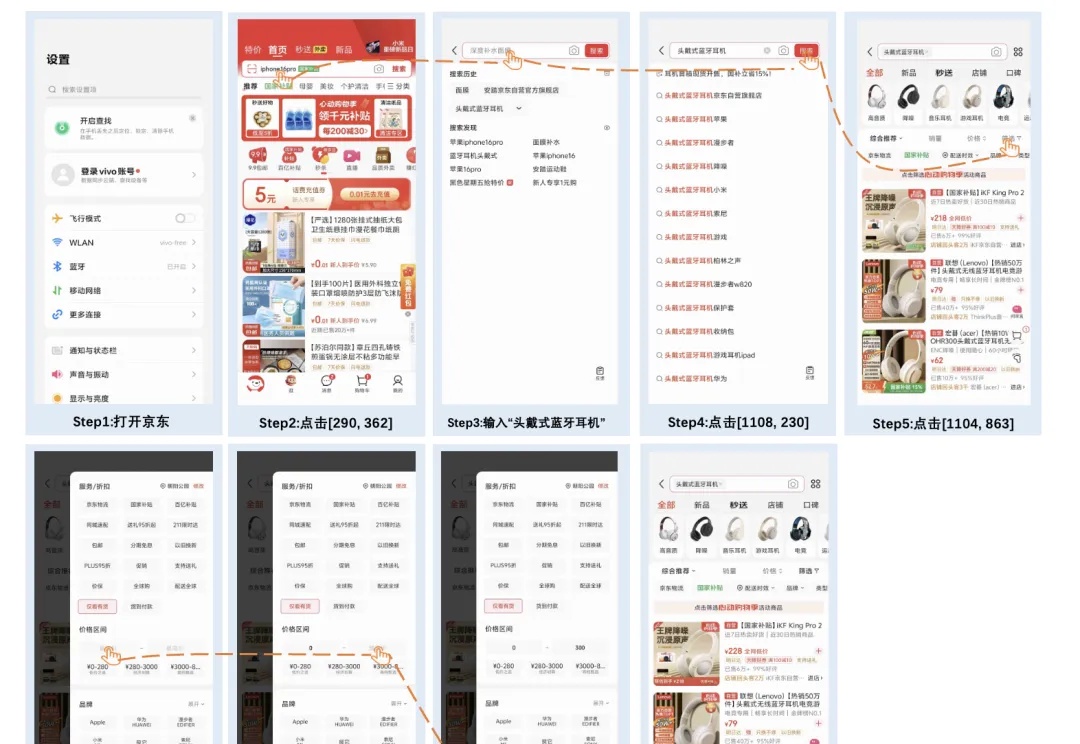
vivo AI Lab发布AI多模态新模型了,专门面向端侧设计,紧凑高效~
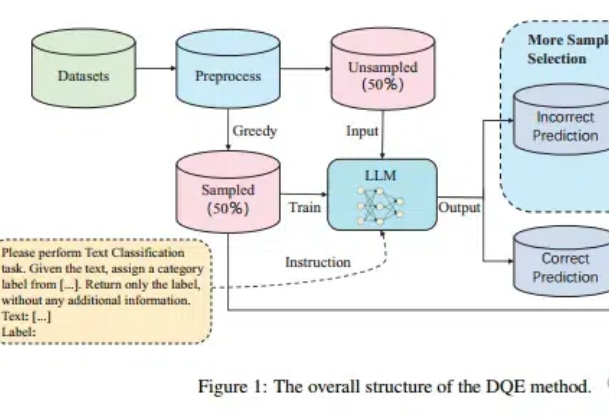
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。

来自中国科学院深圳先进技术研究院、中国科学院大学和 VIVO AI Lab 的研究者联合提出了一个无需训练的文本生成视频新框架 ——GPT4Motion。GPT4Motion 结合了 GPT 等大型语言模型的规划能力、Blender 软件提供的物理模拟能力,以及扩散模型的文生图能力,旨在大幅提升视频合成的质量。